Match Maven
The Match Maven module enables data teams to build and evaluate match-merge models using large language models (LLMs) and embedding-based similarity techniques. It is designed for experimentation, iteration, and optimization of custom entity resolution models that support advanced MDM use cases on Databricks.
Step 1: Model Creation
Access Match Maven via the dedicated navigation card on the LakeFusion interface.
Select the Target Entity you want to experiment on (e.g., Legal Entity, Customer, Product).
Configure the Required Parameters:
Model Name: Enter a unique identifier following naming conventions.
Description: Provide a detailed explanation of the model’s purpose and scope.
LLM Model Selection: Choose from supported large language models.
Embedding Model Specification: Define the embedding model that will generate semantic representations.
Attribute Selection: Select key entity attributes relevant to the match logic.
Select model source from available options:

Databricks foundation models
Databricks custom implementations
External Model API integrations
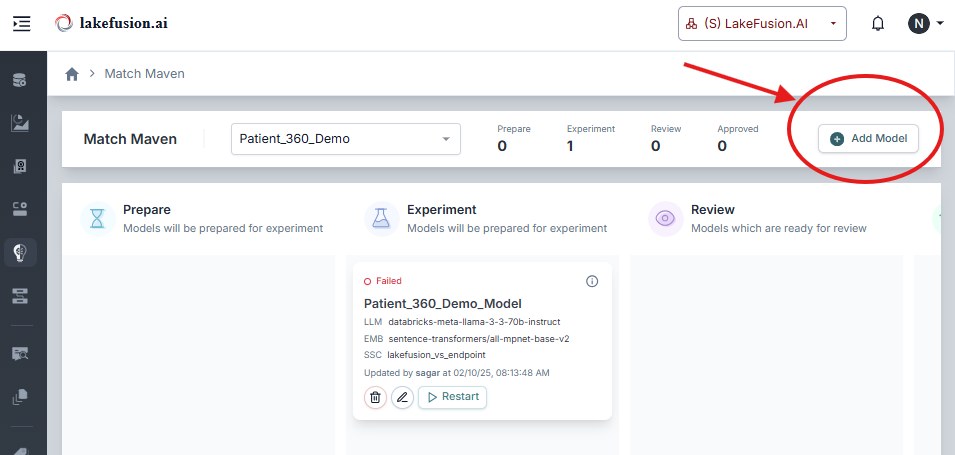
Execute Model Creation by clicking the Add button.

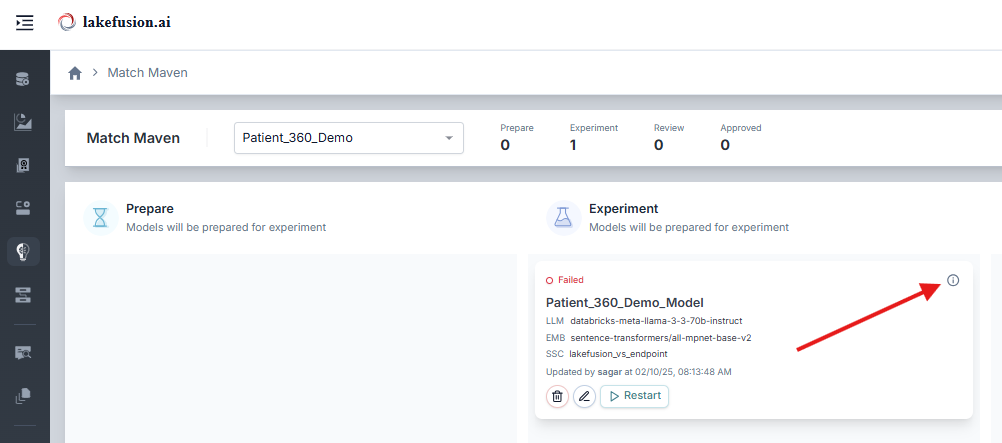
New Feature - Info Button
An Info Button has been added to each experiment entry. Use this to view detailed metadata and insights on the model’s structure, run statistics, and version information.
Step 2: Experiment Execution
Navigate through the four sequential stages:
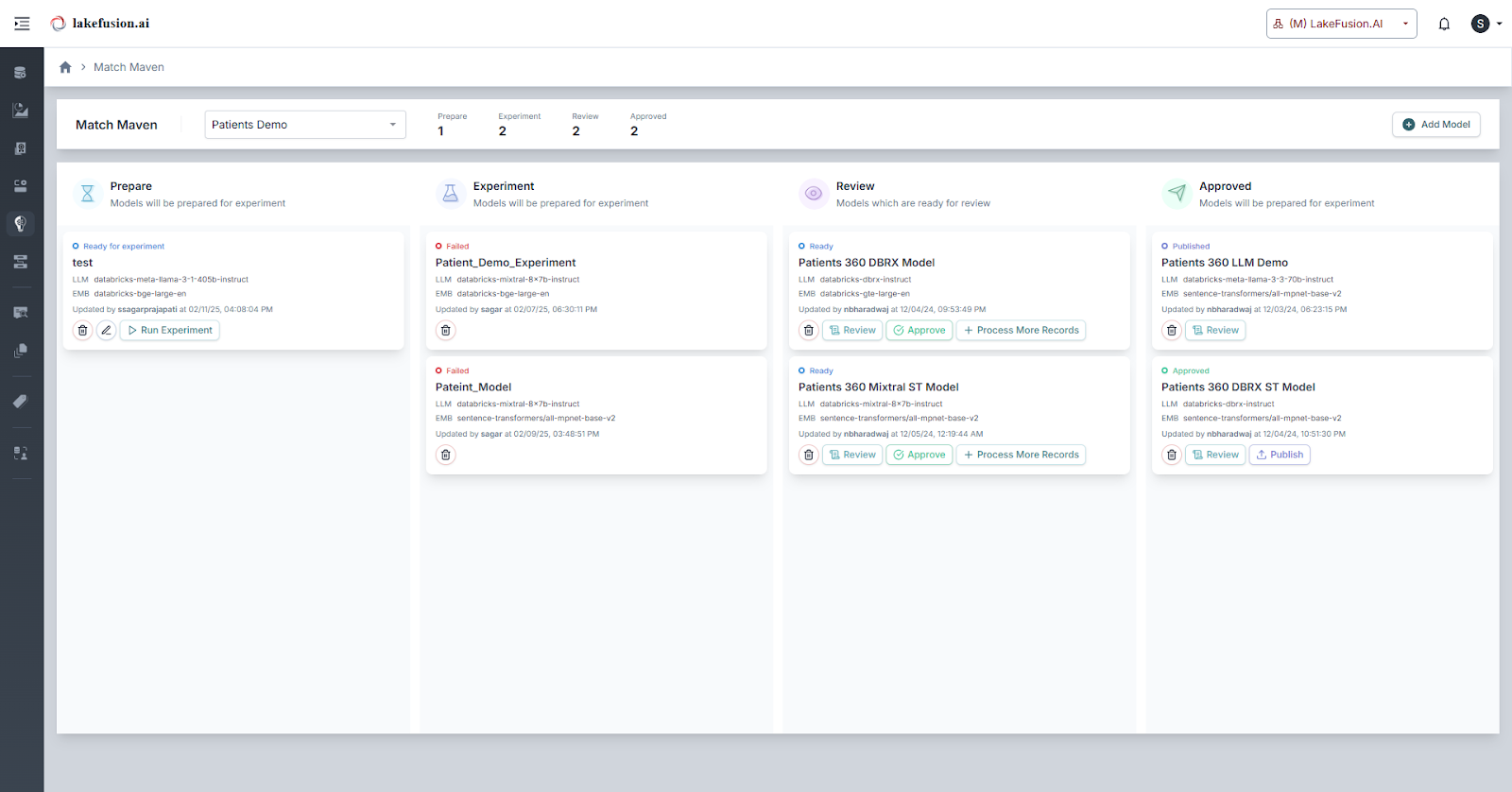
Once a model is defined, run a guided experiment through four sequential stages:
Stage 1 - Prepare
Launch the experiment using the Run Experiment option.
Match Maven will preprocess and organize the input dataset.
Stage 2 - Experiment
The experiment typically runs for approximately 40 minutes, depending on model complexity and data volume.
Real-time progress can be monitored through the dashboard.
During this stage, you can apply custom prompting techniques to influence how the LLM interprets specific data contexts. This helps align the model’s semantic understanding with the business logic behind your matching use case.
Stage 3 - Review
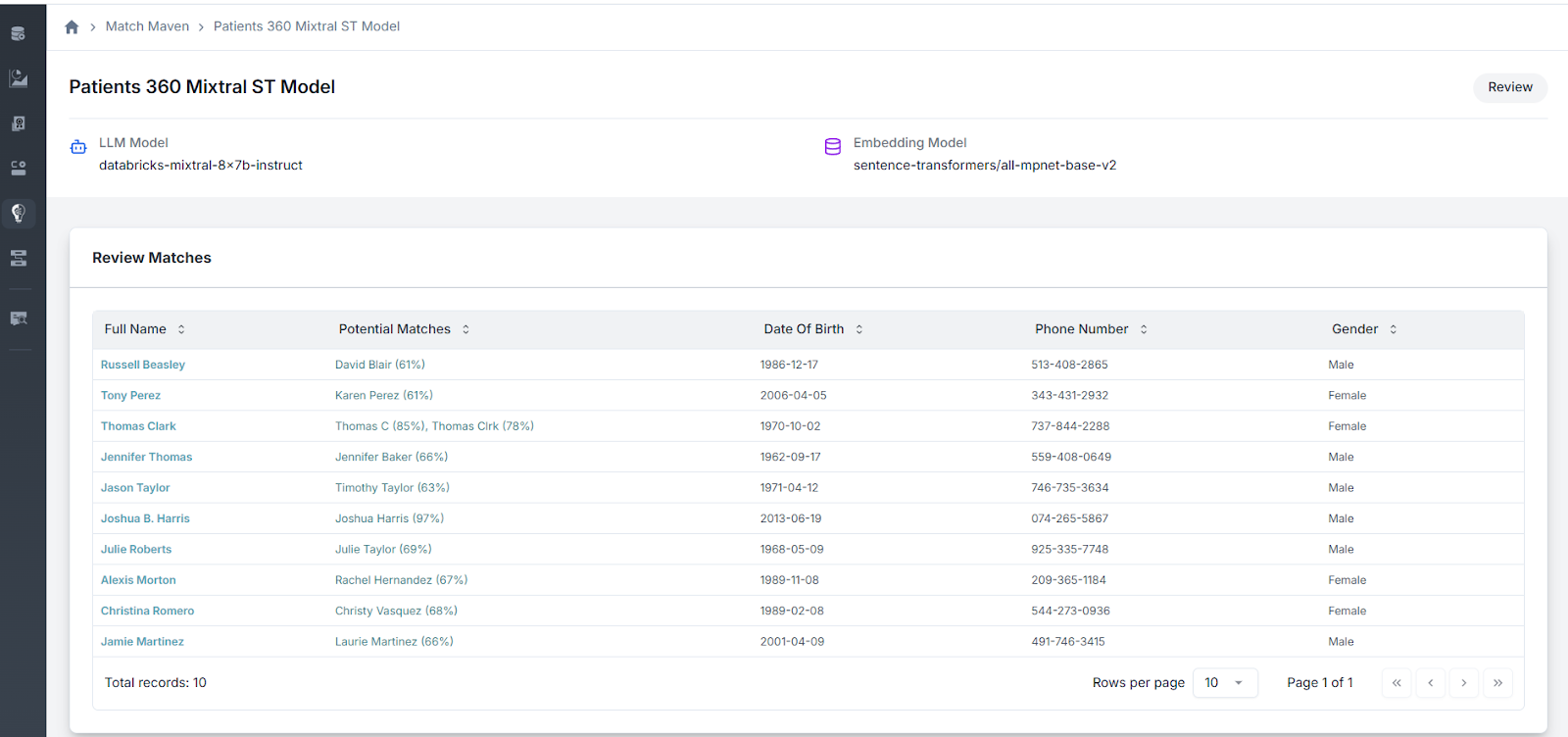
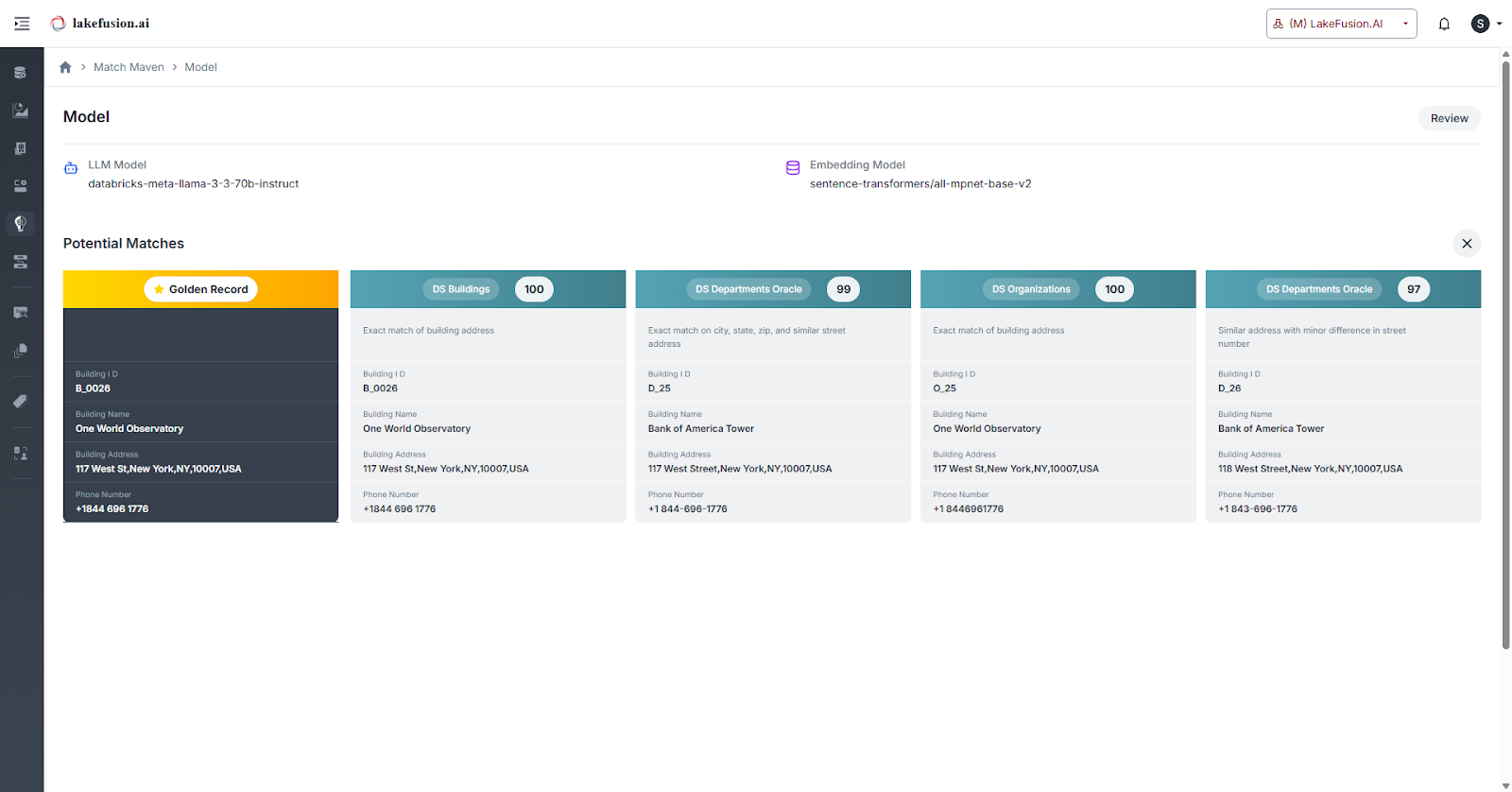
Upon completion, review generated match pairs and evaluate the model’s effectiveness using embedded accuracy and confidence metrics.
You can inspect match results at the record level, compare scores, and analyze the logic driving match decisions.
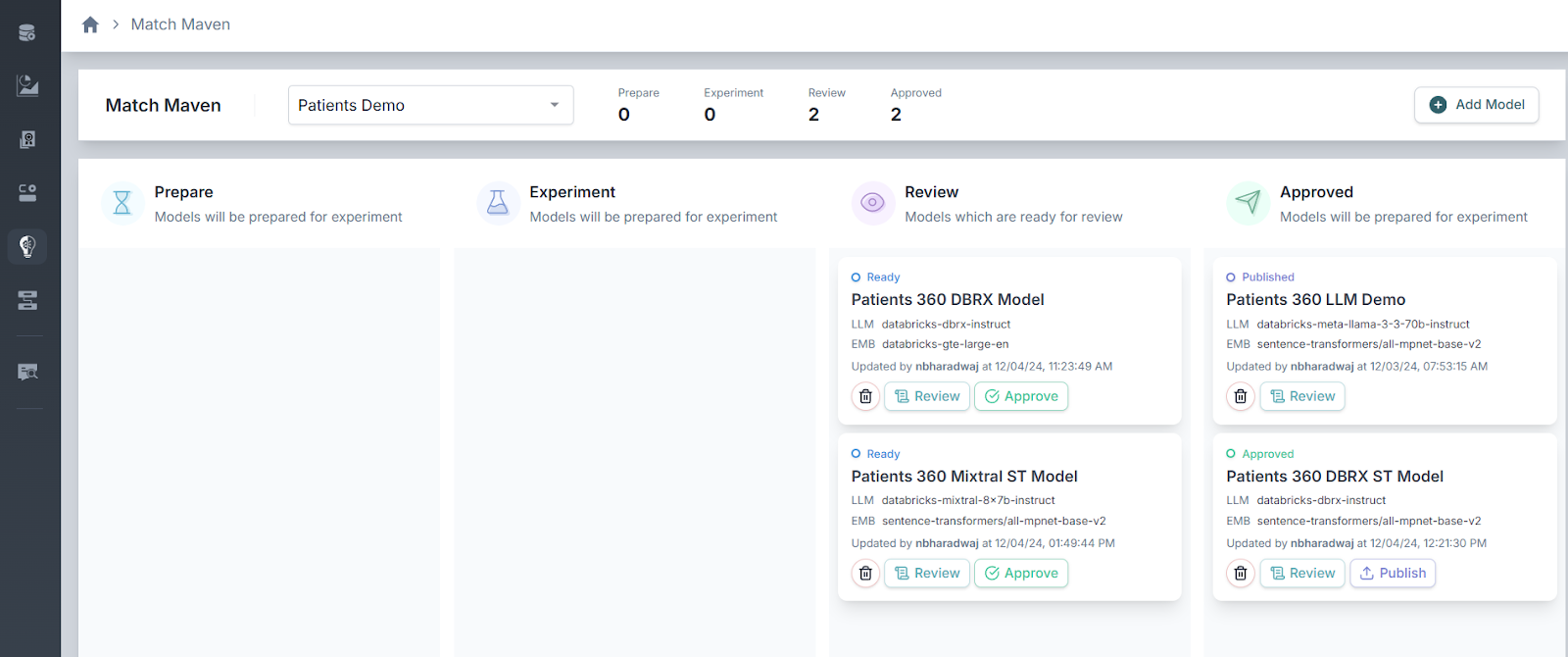
Stage 4 - Approved
If the experiment yields satisfactory results, approve the model to move forward to threshold configuration.
Step 3: Threshold Configuration
Once a model is approved:
Define Merge Thresholds to automatically combine high-confidence matches.
Set Match Thresholds for records requiring manual review.
Establish Non-Match Thresholds to exclude low-confidence pairings from further consideration.
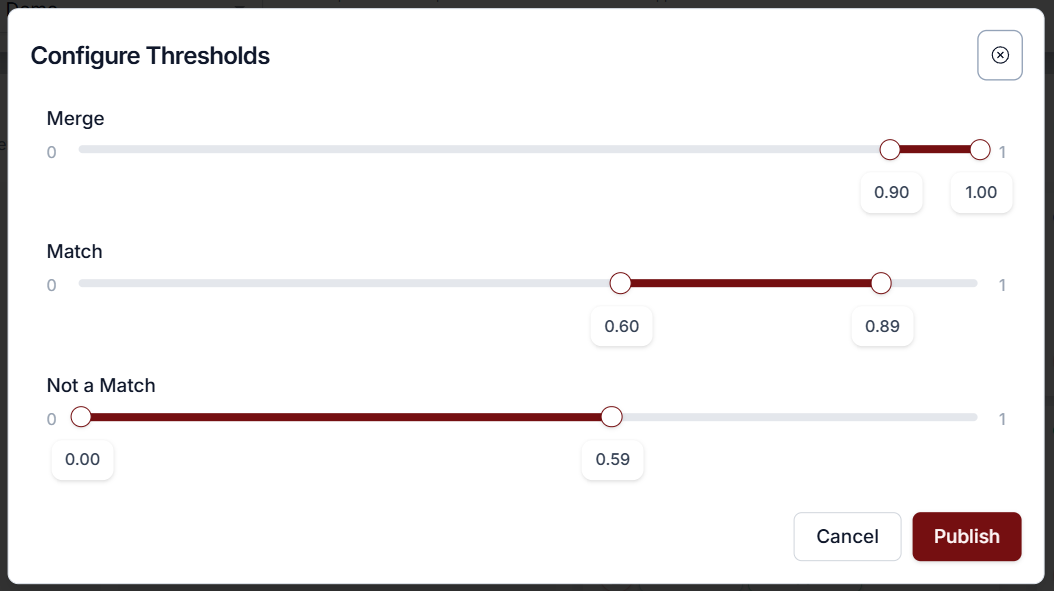
When thresholds are configured and the model is published, notifications are sent to the designated business owner with a prompt to review flagged critical records.
Step 4: Review Record
After publishing, flagged records are accessible via the Entity Search or Notifications Dashboard.
Click on each flagged match to view comprehensive attribute comparisons, source system information, and scoring details.
Evaluate each record to determine whether to merge, exclude, or escalate for further stewardship.
Related Articles
Match Merge Solution
This section outlines the core functionality of LakeFusion's Match-Merge process—a critical feature that resolves duplicate or related records and consolidates them into a single, accurate, and actionable Golden Record. What is the Match-Merge ...Integration Hub
Integration Task creation Navigate to Integration Hub post-Match Maven completion Configure new pipeline with required parameters: Task Name designation Entity selection Model specification Execute task creation Access workflow configuration via ...Troubleshooting Guide
This section outlines known issues encountered during setup or usage of LakeFusion, along with steps to resolve them. 1. Error Accessing the Match Maven Screen Issue: Users encounter an error when attempting to access the Match Maven screen within ...Entity Search
After running Match Maven, LakeFusion sends critical or uncertain matches to Entity Search for manual review and decisions. Step 1: Review Critical Entities Monitor email notifications for critical entity review requests Access Entity Search ...Data Flow in LakeFusion
This section provides a structured overview of the LakeFusion Data Flow, outlining the key stages and enabling technologies that support seamless data ingestion, preprocessing, and Master Data Management (MDM). Each stage ensures data is unified, ...